Drug Classification
Classification • Decision Tree + cross-validation + model visualization

Predict the type of drug a patient should be prescribed based on medical attributes using a Decision Tree Classifier. Features include age, sex, blood pressure, cholesterol, and sodium-to-potassium ratio.
TL;DR
Decision Tree classifier trained on patient attributes, evaluated via 10-fold CV, and visualized for interpretability.
My role
Handled preprocessing/encoding, trained and evaluated decision trees, compared criteria and max_depth settings, and produced a readable tree visualization.
Tech
Links
Dataset
- Source: drug200.csv (Kaggle notebook reference)
- Features: Age, Sex, BP (LOW/NORMAL/HIGH), Cholesterol (NORMAL/HIGH), Na_to_K
- Target: drugA, drugB, drugC, drugX, drugY
Approach
- Preprocessing: Encode categorical variables into numeric values.
- Model: DecisionTreeClassifier (entropy), with
max_depthconstraints to reduce overfitting. - Evaluation: 10-fold cross-validation; report mean accuracy and variability.
- Tuning: Compare
ginivsentropyvslog_lossand test differentmax_depthvalues.
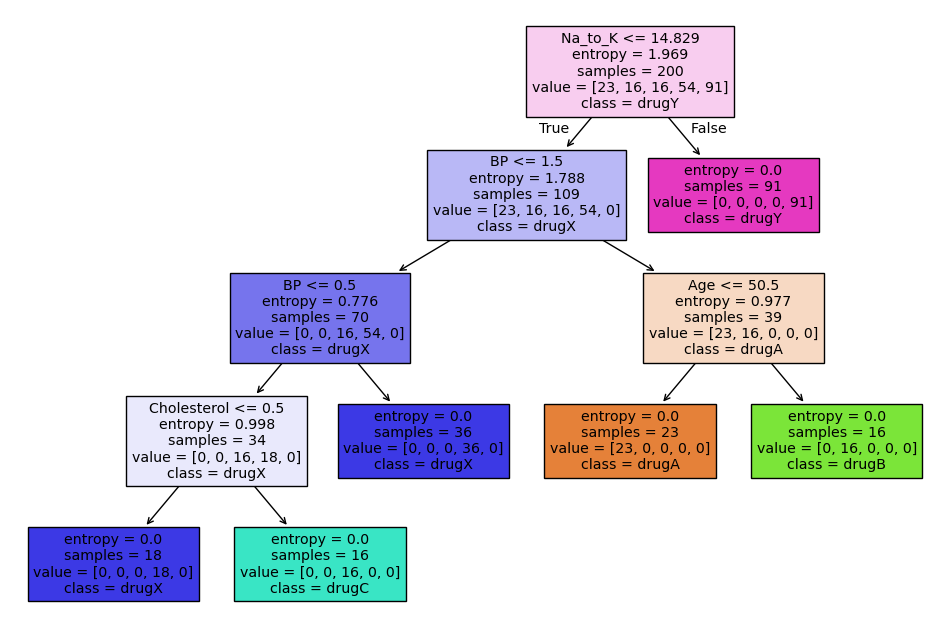
Decision tree visualization
Repository
Explore the code on GitHub: Drug Classification